Final thesis
Judicial Disparities in Seventh Circuit Criminal Appeals
A 53-page empirical thesis on appellate sentencing review, built from a judge-identifying dataset of 1,591 decisions from 2020-2025.

Proof surface
| Claim | Public proof | Private boundary | Status |
|---|---|---|---|
| Dataset size and scope | Full thesis PDF and brief describe the 1,591-decision corpus. | Raw source opinions are public court material but not mirrored as a bulk dataset here. | Final |
| Model frame | Methods section documents the hierarchical Bernoulli-logit GLMM and sensitivity sequence. | Extraction working files and adjudication scratch material stay off-site. | Final |
| Figures | Track shrinkage, issue heatmap, and rank-stability figures are public on the page. | Figure source notebooks are summarized rather than published wholesale. | Final |
Dataset size and scope
- Public proof
- Full thesis PDF and brief describe the 1,591-decision corpus.
- Private boundary
- Raw source opinions are public court material but not mirrored as a bulk dataset here.
- Status
- Final
Model frame
- Public proof
- Methods section documents the hierarchical Bernoulli-logit GLMM and sensitivity sequence.
- Private boundary
- Extraction working files and adjudication scratch material stay off-site.
- Status
- Final
Figures
- Public proof
- Track shrinkage, issue heatmap, and rank-stability figures are public on the page.
- Private boundary
- Figure source notebooks are summarized rather than published wholesale.
- Status
- Final
Core question
The thesis asks whether apparent differences in Seventh Circuit sentencing relief are best explained by stable judge traits or by the institutional organization of appellate review itself.
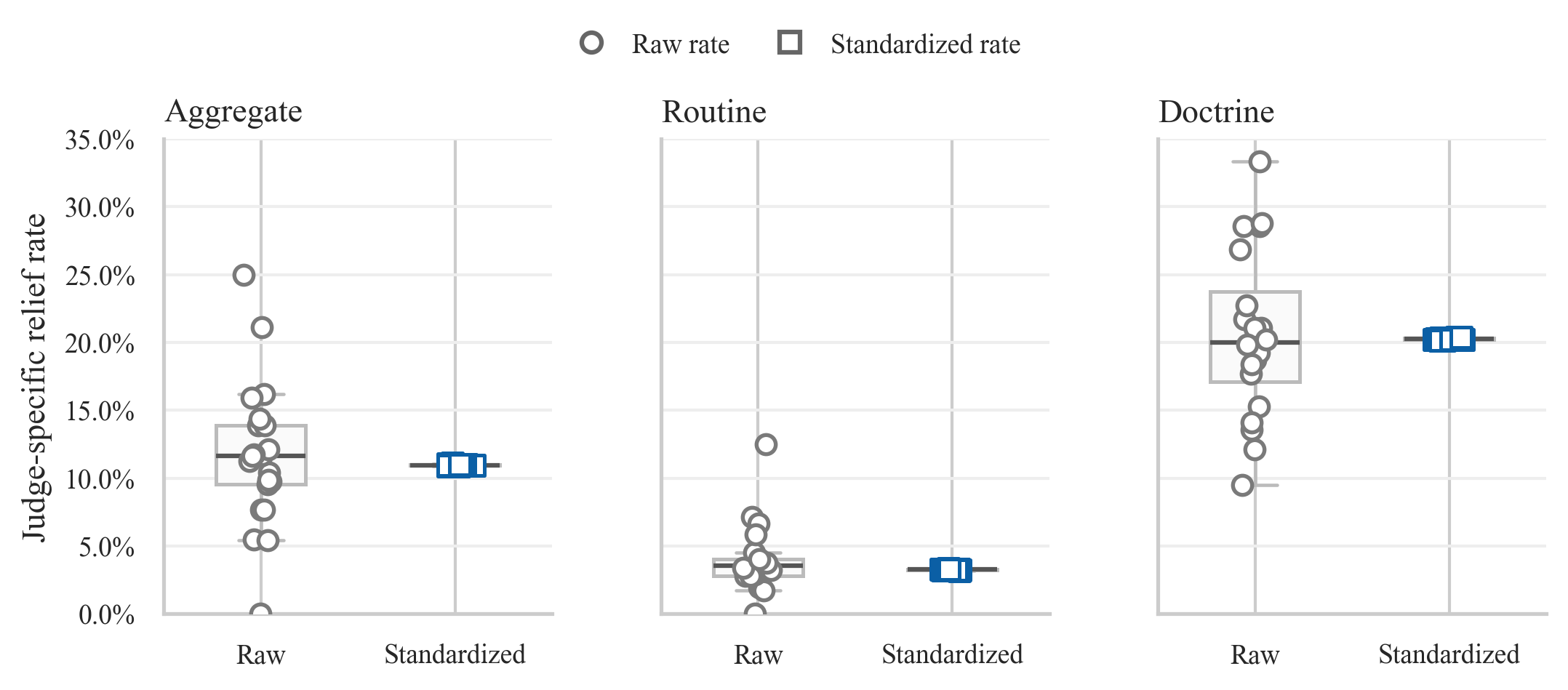
The simple story does not survive the model. Raw judge-by-judge rates appear wide at first glance. After the docket is separated into publication tracks and standardized for case composition, most of that spread narrows sharply. The sharpest divide is the low-relief nonprecedential track versus the higher-relief precedential track.
If the 53-page thesis has to become one page, the spine is this: published appellate doctrine and ordinary unpublished sentencing review occupy separate statistical environments. Treating them as one pool makes judge disparity look more personal than it is. Splitting them by institutional track shows a publication system with two very different relief baselines.
What the dataset covers
The source universe begins with the Seventh Circuit's public repository of opinions, nonprecedential dispositive orders, and oral-argument materials. The pipeline starts from 6,011 raw records, narrows to 1,853 criminal downloads, deduplicates them into 1,591 unique criminal decisions, and then builds the final sentencing merits universe.
The final analysis separates the docket into three tracks:
- Aggregate: the full modeled sentencing merits stream.
- Routine: unpublished, nonprecedential dispositions.
- Doctrine: published precedential opinions.
That split matters because publication status changes the relief environment. Routine contains slightly more than half of the modeled decisions but has a much lower relief rate. Doctrine contains slightly less than half of the decisions but a much higher relief rate.
- 6,011 raw Seventh Circuit records
- 1,853 criminal opinion downloads
- 1,591 deduped criminal decisions
- 1,375 merits decisions
- 4,157 judge-vote rows
How it was built
The pipeline deduplicates source PDFs with byte, text, and visual checks. It then uses a segmented, schema-constrained LLM extraction system to code panel membership, publication status, posture, offense category, issue category, and relief outcome.
Each extracted field carries both a value and a status marker: present, not mentioned, unclear, or not applicable. That design makes missingness visible instead of silently treating short appellate dispositions as if they said more than they did.
The decision-level table is expanded into a judge-vote table, one row for each judge participating in each case. Because panel judges share the same case-level outcome, the model includes a case-level random intercept rather than pretending those rows are independent sentencing events.
Statistical frame
The model is a hierarchical Bernoulli-logit generalized linear mixed model fit by Markov Chain Monte Carlo with the No-U-Turn Sampler. Judge rates are standardized against a common reference docket so judges are compared on the same mix of case types rather than on whatever portfolio happened to reach their panels.
The design is deliberately conservative. It asks whether judge-level differences remain after accounting for posture, offense composition, publication track, uneven exposure, and shared panel outcomes.
sentence_relief_i ~ Bernoulli(pi_i)
logit(pi_i) = alpha + X_i beta + u_judge[j(i)] + u_case[i]
u_judge ~ Normal(0, sigma_judge)
u_case ~ Normal(0, sigma_case)
Standardized judge rate:
average predicted relief for judge j on the same reference docketThe case-level random intercept is substantive. It corrects the obvious dependence problem created when a three-judge panel decision becomes three judge-vote rows. Without that term, the model would treat panelmates as independent sentencing outcomes.
Main findings
| Track | Decisions | Relief | Disparity audit |
|---|---|---|---|
| Aggregate | 1,375 | 11.23% | 2.84x, p < 0.001 |
| Routine | 728 | 3.44% | 1.23x, p = 0.212 |
| Doctrine | 647 | 19.83% | 1.35x, p = 0.172 |
The Aggregate docket still shows excess residual spread. But the two publication tracks do not show strong excess within-track disparity once the model standardizes for case composition. Routine and Doctrine have very different baseline relief rates, and the gap between those tracks is far larger than the standardized differences associated with party, gender, race, or professional background.
Party and gender differences exist directionally but remain small. Democratic appointees sit slightly higher than Republican appointees after standardization, and female judges sit slightly higher than male judges, but those gaps are measured in low single-digit percentage points. Race is too thinly distributed in the sample to support a strong group-level account. Profession is overlapping and partly confounded, though law-professor backgrounds sit somewhat higher in some tracks. Age and tenure show the clearest gradients, but even those are modest relative to publication track.
Robustness logic
The sensitivity sequence is the compact version of the statistical argument. Adding posture and offense controls barely changes fit. Adding publication status moves the model dramatically. A standard-of-review grouping adds only a modest further gain. That pattern reinforces the same conclusion from the three-track analysis: the major omitted distinction inside the criminal merits stream is publication track.
| Model block | Tail loss | Delta | Judge sigma |
|---|---|---|---|
| Baseline | 1507.0 | 0.0 | 1.012 |
| Posture | 1502.5 | 4.5 | 1.011 |
| Offense | 1508.2 | -5.7 | 1.060 |
| Publication | 1379.6 | 128.6 | 1.135 |
| Std. review | 1372.4 | 7.2 | 1.183 |
Institutional takeaway
Published sentencing opinions are indispensable for understanding lawmaking moments, but they do not fully describe the appellate environment most litigants face. Most sentencing appeals are resolved through lower-visibility adjudication, and that track is more compressed, less correction-oriented, and less visibly differentiated by judge-specific traits.
That means studying published doctrine alone can misidentify where disparity lives. The thesis argues for a track-specific account of appellate sentencing review: what the court says when it makes precedent, and how ordinary sentencing appeals are processed across the full merits stream.
Artifacts
- The full thesis is available above as a PDF.
- The brief version remains linked for a quick scan.
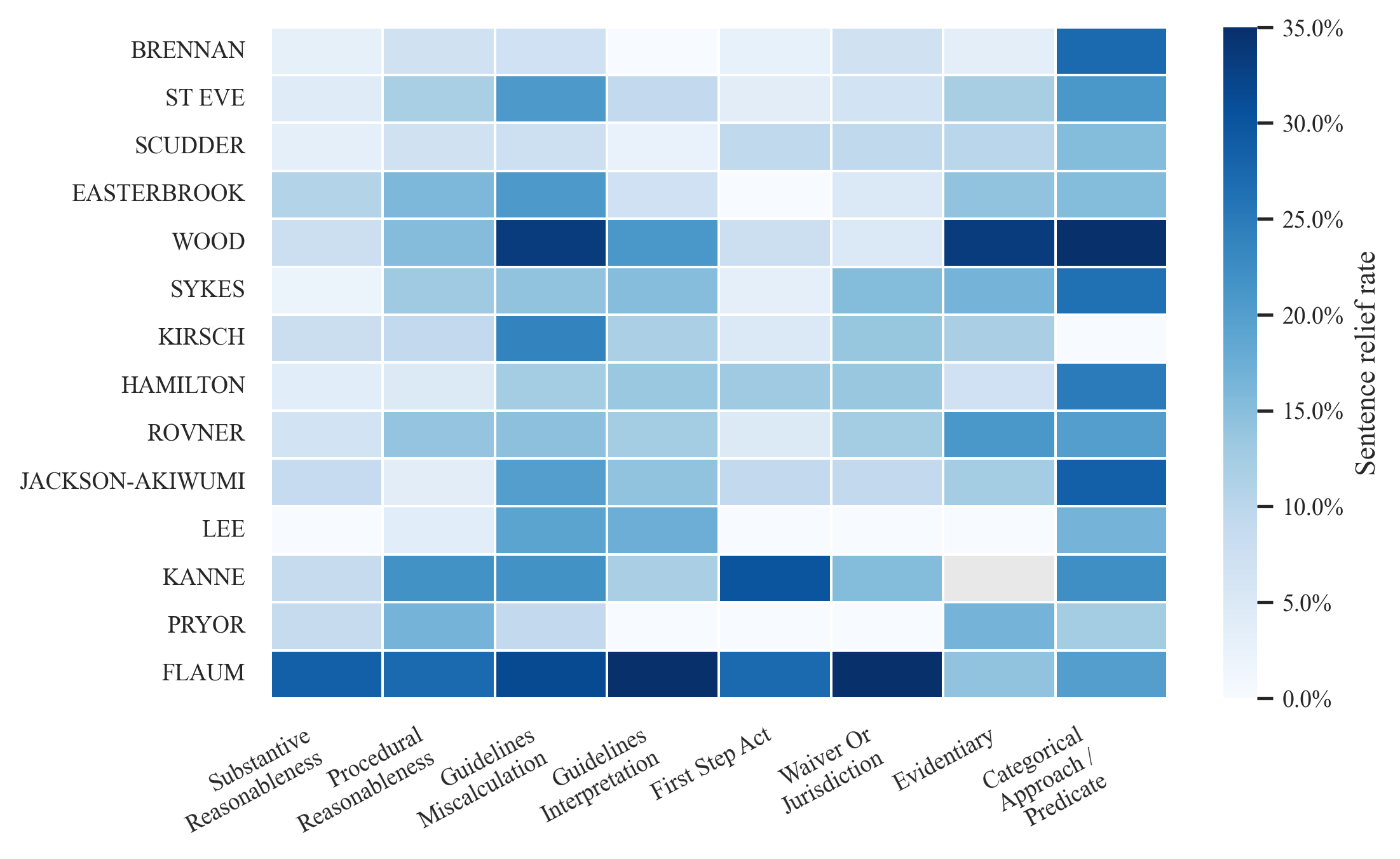
- The figure set includes raw and standardized judge rates, issue and offense heatmaps, track-level shrinkage, and rank-stability checks.